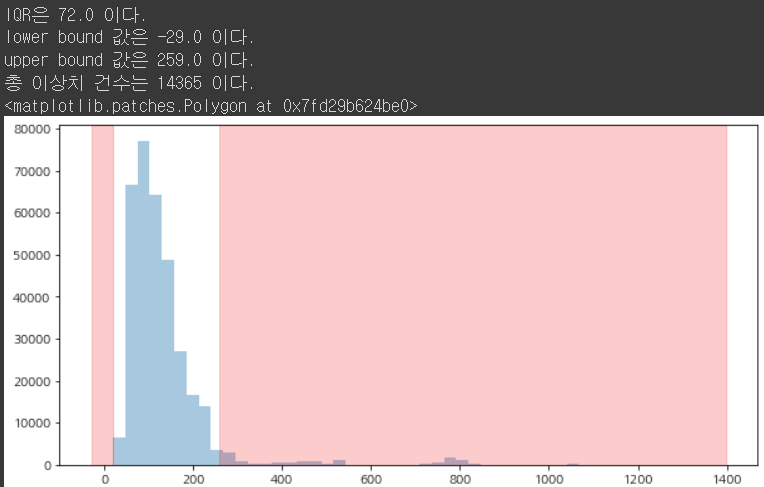
IQR 을 이용해 통계학적 이상치를 알아보는 코드
## 이상치
- 이상치 = 극단치 + 특이치
- 극단치는 제거하는 것이 모형에 좋다 >> 통계적 자료 분석의 결과 왜곡 > 보정 또는 삭제
- 특이치는 그대로 사용하는 것이 모형에 좋다 >> 중상적인 수집과정에 의한 이상치(이전까지 보지 못한 패턴이나 데이터)
## 이상치(outlier) 탐지 관련 참조 사이트
https://kr.machbase.com/deep-anomaly-detection-in-time-series-2-anomaly-detection-models/
기존 이상치 탐지 방법의 주요 종류
- 3-sigma : 정규 분포에서 3표준편차의 범위 외의 데이터를 이상 데이터 취급
- boxplot : 사분위수(Quartile)와 사분범위를 이용하여 이상 데이터의 기준을 정하는 방법
- ARIMA : 자기회귀누적이동평균, 원래는 시계열을 예측하는데 주로 이용, 이를 이용해 미래의 시계열을 예측한 후,관측 데이터와의 오차 혹은 관측값이 발생할 확률 등을 통해 이상 데이터를 판별 - 단변량(단일변수) 시계열에만 국한되어 있음 >> 단변량에 비해 불확실성이 클 수 밖에 없는 다변량 시계열의 경우 예측 기반의 이상 감지는 큰 도움이 되지 않을 수 있음
비지도학습 기반 이상 감지
- 오토인코더 : 입력 데이터를 보다 작은 차원의 데이터로 압축하는 Encoder와, 압축된 데이터를 다시 입력 데이터와 가깝게 복원하는 Decoder로 이루어져 있음, >> 고차원의 데이터를 더 간단하게 표현할 수 있는 저차원의 공간이 있다는 가정 필요 데이터의 양이 매우 적은 이상 데이터의 특징은 포함되기 어려움, 그렇다면 학습이 끝났을 때 AutoEncoder에 정상 데이터를 넣으면 정상적으로 복원된 출력이 나오겠지만, 이상 데이터를 넣는다면 이상 데이터의 특징은 잘 추출되지 않고 대신 입력 데이터와 그나마 가장 가까운 정상 데이터가 나올 것, 입력 데이터와 출력 데이터의 차이는 정상 데이터에 비해 클 수 밖에 없고, 이러한 차이를 이용하여 이상 데이터 감지
# 4분위수를 이용한 이상치를 확인
https://colinch4.github.io/2020-12-04/outlier/
- 사분위수 설명
- 제 1 사분위수(Q1) 데이터의 25%가 이 값보다 작거나 같다.
- 제 2 사분위수(Q2) 중위수, 데이터의 50%가 이 값보다 작거나 같다.
- 제 3 사분위수(Q3) 데이터의 75%가 이 값보다 작거나 같다.
- 사분위 범위(IQR) Q3 - Q1, 데이터의 중간 50%에 대한 범위이다.
- 이상치
- 제 1 사분위수 - 1.5 * IQR 보다 작은 수
- 제 3사분위수 + 1.5 * IQR 보다 큰 수
<코드 실행하면 아래의 그림과같이 표현된다.>
'python' 카테고리의 다른 글
| [python]파이썬 isdigit() - 백준 1620 파이썬 (0) | 2024.08.06 |
|---|